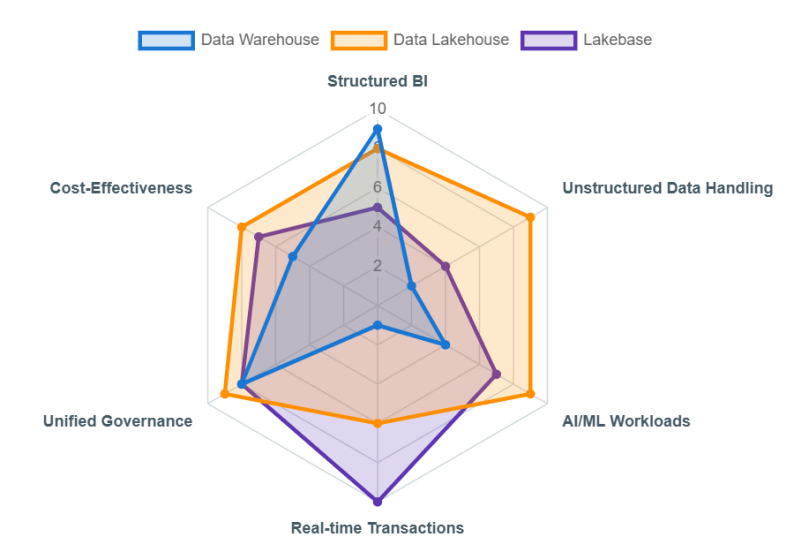
The landscape of data management has dramatically shifted from rigid, siloed systems to flexible, integrated platforms designed to handle the unprecedented volume, variety, and velocity of modern data. This evolution is driven by the increasing demand for real-time insights, advanced analytics, and sophisticated AI/ML capabilities across all business functions.
Read More »